Definition
Say you have a set of vectors, and you need to define how similar/different they are from each other.
There are many different approaches to measure the distances between vectors. All these approaches must obey (at least) the following basic rules in order to be referred to as a metric:
Given a real-valued function d : X × X → R
- Positivity: Distance(X, Y) ≥ 0
- Identity: Distance(X, Y) = 0 <=> X == Y
- Symmetry: Distance(X, Y) == Distance(Y, X)
- Triangular Inequality: Distance(X, Z) ≤ Distance(X, Y) + Distance(Y, Z)
The most commonly used metrics
Euclidean distance (a.k.a. 2-norm)

Manhattan distance (a.k.a. City-Block, 1-norm)
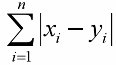
Cosine correlation coefficient
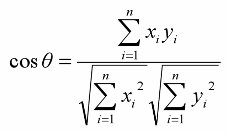 (where θ is the angle between the vectors)
(where θ is the angle between the vectors)The thing is that there are many many more distance measures, each with specific qualities. For each problem you may need to use a different metric, usually based on some empyrical tests.
Additional metrics
Following is a list of additional metrics, for more details about each, please refer to the links at the bottom:
- p-norm (a.k.a. Minkowski distance of order p): same as 2-norm, just replace the 2 with p, where p is a real number > 1.
- infinity-norm: like p-norm with p → infinity.
- Pearson correlation coefficient, Uncentered Pearson correlation coefficient, Squared Pearson correlation coefficient: all are very similar to the Cosine correlation coefficient.
- Averaged dot product: the dot product of the two vectors, devided by the number of elements in the vector. Very simple, probably too simple in most cases.
- Rank correlation methods: non-parametric methods that look at the rank of the values instead of the values themselves.
- Canberra Distance: often used to detect abnormalities, since it has a bias for distances around the origin.
- Chi-square: often used in statistics, to determine how well an observation fits the theory.
- Mahalanobis distance: similar to Euqlidien distance, except that it also takes into account the correlations of the data set and is scale-invariant.
Sources and additional references
http://axon.cs.byu.edu/~randy/jair/wilson2.html
http://en.wikipedia.org/wiki/Distance
http://en.wikipedia.org/wiki/Metric_(mathematics)
http://en.wikipedia.org/wiki/Kendall
http://en.wikipedia.org/wiki/Spearman
http://en.wikipedia.org/wiki/Mahalanobis_distance
http://genome.tugraz.at/Theses/Sturn2001.pdf
http://www.ucl.ac.uk/oncology/MicroCore/HTML_resource/distances_popup.htm
http://www.ucl.ac.uk/oncology/MicroCore/HTML_resource/Distances_detailed_popup.htm
http://axon.cs.byu.edu/~randy/jair/wilson2.html
http://149.170.199.144/multivar/dist.htm
http://en.wikipedia.org/wiki/Norm_(mathematics)


No comments:
Post a Comment